The document function, used via the from clause as previously presented, allows you to integrate, into the ODT result, images or files.
Importing images
The following example imports an image from disk.
Parameter at allows to specify the (preferably absolute) path to the image on disk. Note that, in the Python 3 version of Appy, you can place an instance of pathlib.Path in this parameter as well.
The result is the following.

You find this logo ugly? Concentrate yourself on functionality! POD deduced the file type from the file extension. The following file extensions are recognized.
| Extension |
Format |
| 'png' |
PNG |
| 'jpeg' or 'jpg' |
JPEG |
| 'gif' |
GIF |
| 'svg' |
SVG |
By default, the image has been imported anchored as character. If you want to use another anchoring, use parameter anchor. Possible values are strings as-char (as character, the default), char (to character), paragraph (to paragraph) and page (to page).
It is also possible to specify an URL to parameter at. In the following example, an image is imported from a website.

The result is as follows.

Don't be scared, please continue reading!
Historically, there was an alternate way to import images. Instead of using parameter at, a combination of parameters content and format was allowed:
- parameter content had to store the file's binary content (ie, retrieved by a command like: with open(pythonFile, 'rb') as f: content = f.read());
- parameter format had to specify the file format, as a string from column "Extension" from the hereabove table.
Although this method still works, it could be removed in the future, so it is not recommended to adopt it for new developments.
When the same image is imported several times in your POD template, POD remembers it and stores a single copy of it within the ODT result.
Importing documents
With the document function, it is also possible to import complete documents within the ODT result. The example below imports the content of another ODT document into the ODT result.

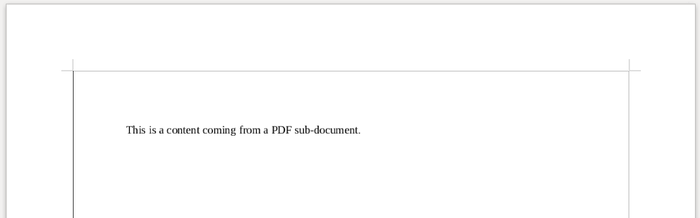
The content of the sub-document to import (sub.odt) is the following.

Here is the result.

As mentioned in the screenshots, LibreOffice is required to run in server mode, behind the scenes. Indeed, this functionality is implemented as follows: POD inserts, in the POD result, a section tied to an external file, and then, asks LibreOffice running in server mode to resolve these sections. Resolving means: re-incorporating, in the master document, the content of sections pointing to external sub-documents.
It is also possible to import PDF documents within the ODT result. For this case, another technique is used: LibreOffice is not required to run in server mode, but Ghostscript will be called to convert the PDF file into one image per page. Then, POD will fallback to the case of importing images into the ODT result.
Suppose we have converted sub.odt to sub.pdf and we have modified the ODT template to import the PDF instead:

The result will be the following.
Here, the result is less subtle: the PDF is splitted into one image per page, and the ODT result contains page-wide images, one per page.
Finally, POD can also incorporate, via the document function, documents in any format that LibreOffice can convert to PDF: doc[x], xls[x], RTF... It is thus possible to write comments like this one:
do text
from document(at='/some/microsoft/word/document.docx')
LibreOffice running in server mode is required for this to work. POD will call it to convert the Word document to PDF; then, POD falls back to the PDF import, will split the PDF into one image per page via Ghostscript and will integrate every image in the ODT result.
Reference
The document function, as available in the default POD context, corresponds to method importDocument defined on class Renderer. You will find hereafter the complete function signature, with a detailed explanation of every parameter.
 def importDocument(self, content=None, at=None, format=None,
anchor='as-char', wrapInPara=True, size=None, sizeUnit='cm',
maxWidth='page', maxHeight='page', style=None, keepRatio=True,
pageBreakBefore=False, pageBreakAfter=False, convertOptions=None):
'''Implements the POD statement "do... from document"'''
def importDocument(self, content=None, at=None, format=None,
anchor='as-char', wrapInPara=True, size=None, sizeUnit='cm',
maxWidth='page', maxHeight='page', style=None, keepRatio=True,
pageBreakBefore=False, pageBreakAfter=False, convertOptions=None):
'''Implements the POD statement "do... from document"'''








