A common use case, when dumping information as a table in a POD result, is to highlight some rows or cells, by applying a specific background color.
With what we've learned so far, such formatting can be applied, but with restrictions, repetition and inelegance.
Suppose you have developed a webapp for managing software products. Each one has a name and a list of features; every feature has these characteristics:
- a title,
- a version number, corresponding to the version into which the feature has been introduced,
- the fact that the feature is a major or minor feature.
Then, for a given software product, you want to export an ODT file containing a table, listing all features. You want the major features to be rendered in rows with a grey background; the minor features mus be dumped with a white background color.
You could use this template.

Call this template with the following code:
from appy.pod.renderer import Renderer
from appy.model.utils import Object as O
software = O(
name='Appy',
features=[
O(title='Fix images import', version='1.0.6', major=False),
O(title='Allow to set ooPort to None', version='1.0.6', major=False),
O(title='Style cells', version='1.0.6', major=True),
])
Renderer('DirtyFeatures.odt', globals(), 'DirtyFeatures.result.odt',
overwriteExisting=True).run()
And you will get this result.

This dirty technique consisted in creating a section, repeated for every feature. Within that section, 2 one-row tables are defined, each one with exactly the same content, but with a different background. For every feature, the table with the correct background is chosen or dismissed via if/else statements, depending on the feature being major or not. Dirtyness shines at several levels.
- The POD template is over-structured. It is not possible to do the job with a single table, so we have to create 2 one-row tables within a section. Structurally, LibreOffice forces us to insert a paragraph before and after the table, within the section. So, in order to avoid having these empty paragraphs in the POD result, 2 statements « do text if False » must be set on it. That being said, even when you'll get your « not-dirty-POD-developer » label, you will still encounter situations where this technique must be applied. So keep that in mind.
- A part of the POD template is repeated. In this simple example, it is not that bad: the part is reduced. But imagine you have more columns, more statements and/or expressions within each column: it could become a headache to maintain copies of a more complex row.
- The POD result is over-structured. It looks nice, but it includes a series of one-row tables instead of a single table. This can be a problem, if, for example, you defined table headers and wanted it to be repeated if the table spanned multiple pages. Moreover, if you planned to convert the POD result to a format like Microsoft Word, such over-structure may lead to bugs in the end result. LibreOffice filters, responsible for performing such conversions, are good and continuously improved, but you will always have surprises and it is preferable to design your POD templates for producing the simplest possible ODT results.
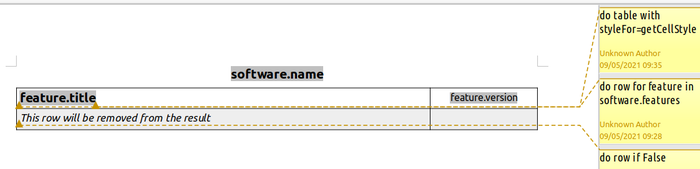
The nice technique is illustrated by the following POD template.
If you use it with the following Python code:
from appy.pod.renderer import Renderer
from appy.model.utils import Object as O
software = O(
name='Appy',
features=[
O(title='Fix images import', version='1.0.6', major=False),
O(title='Allow to set ooPort to None', version='1.0.6', major=False),
O(title='Style cells', version='1.0.6', major=True),
])
def getCellStyle(style, ctx):
'''Get the style to apply to the current cell in the current table'''
if ctx['feature'].major:
# A grey background must be applied
r = style[:-1] + '2'
else:
r = style
return r
Renderer('NiceFeatures.odt', globals(), 'NiceFeatures.result.odt',
overwriteExisting=True).run()
You will get this result.

While it looks the same as the dirty one, structurally, it contains a single nice table, and not 3 disgracious one-row tables. The trained eye can detect it by inspecting table borders.
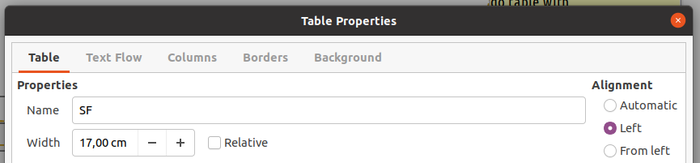
Before explaining what happened here, you must know that this technique is, for performance reasons, not applied on all tables included in your POD templates. In order to enable it on a specific table, its name must be changed and start with an uppercase S. In the POD template, I have renamed the table as SF.
A second thing to know is that LibreOffice generates names of table cells based on the table name, row and column numbers. In the hereabove template, LO has generated one style for every cell, named:
- SF.A1 (first row =1, first column=A)
- SF.B1 (first row=1, second column=B)
- SF.A2 (second row=2, first column=A)
- SF.B2 (second row=2, second column=B)
If the table contains more cells, and if groups of cells have exactly the same layout, LO may reuse the same style for several cells.
Let's now explain the example step by step. The POD template is simpler: there is no section and a single table. The first row is repeated for every feature, while the second row, whose sole purpose is to ensure a cell style with a grey background is included in the POD template, will be removed from the result, via statement « do row if False ».
The most important element is the definition of a variable named styleFor, on the table, initialised with function getCellStyle. When this variable is present, POD understands you want to cheat with the styles of the cells belonging to the table, and will call the function for evey cell in the table. POD will call it with 2 args:
- the name of the style that must normally be applied to the current cell;
- the POD context.
The function must return the style to apply. It is a kind of very specific "style mapping" facility, only applicable to ODT table cells.
The POD context allows you to retrieve the current feature, via key 'feature'. In the example, if the feature is:
- minor, you don't change anything and return the passed style;
- major, you decide to use the style of the "grey" row, same cell, via expression style[:-1] + '2'. For example, style "SF.B1" is replaced with "SF.B2" (= the greyed variant).
This is not for ODS
This technique only applies to ODT table cells, not ODS. Styling ODS cells is achieved via the « cell » function.








