POD is based on the OpenDocument standard and is able to read and write documents in that format. More precisely, POD reads and writes documents in these formats:
- OpenDocument Text (ODT);
- OpenDocument Spreadsheet (ODS).
Consequently, as long as you do not need to generate documents in other formats than these ones, and as far as you don't need functionalities as described below, it is useless to use Appy in conjunction with LibreOffice running in server mode. This latter becomes required if:
- you want to produce documents in other formats, like PDF, DOC, DOCX, XLS, XLSX or CSV;
- you want to perform some actions on the resulting ODT or ODS file as generated by POD, like:
- updating its table of contents or other fields;
- incorporating sub-documents into the main document via POD functions document or pod;
- using LibreOffice's algorithms for optimizing the size of table columns,
- ...
In most cases, it is obvious, at the POD level, whether LibreOffice must be called or not. Tell POD to produce a PDF file; insert, in your POD template, a note with a call to the pod function: POD will automatically decide to call LO. In other cases, this decision is not so obvious. POD does not automatically call LO, for the sake of performance and simplicity. Suppose you have a table of contents in your POD template. The POD result will still contain the table, but its content may not be up-to-date anymore with the new document content. POD is not able to recompute the table of contents itself. Its developer(s) is (are) not that crazy. Instead, this is the kind of things that can be asked to LibreOffice itself, via UNO commands. Suppose you define this Renderer instance:
renderer = Renderer('This_template_includes_a_TOC.odt', globals(), 'result.pdf')
As its name strongly suggests, the POD template contains a table of contents. The result being a PDF file, recomputing the table of contents will be done anyway, because LO is systematically called. Suppose now you define this instance.
renderer = Renderer('This_template_includes_a_TOC.odt', globals(), 'result.odt')
If nothing, in your POD template, forces POD to call LO (the simple presence of a table of contents is not sufficient), POD will not call LO and the table of contents might not be correct in result.odt. if you want to ensure POD will call LO, use parameter forceOoCall, like this.
renderer = Renderer('This_template_includes_a_TOC.odt', globals(), 'result.odt', forceOoCall=True)
Parameter forceOoCall is not called forceLoCall for historical reasons.
Everytime POD calls LibreOffice, the following tasks are systematically performed on the POD ODT result via UNO commands. For ODS, no task is performed.
- All indexes are updated.
- All fields are updated, including the table of contents. This latter is the very last operation performed on the POD result: indeed, any other command may potentially impact it.
- Sections containing links to external files (like those produced by POD functions document or pod) are disposed: they are replaced with the content of the linked file.
Running and managing a LibreOffice (LO) server
Warning - Currently, the examples from this section are mainly provided for a Ubuntu server. Do not hesitate to send me examples for other platforms, I'll be glad to complete this site with your contributions or add links to your pages.
Installing LibreOffice
Ensure you are root on the machine you are about to install LO, by typing:
sudo su
As a prerequisite, you may want to configure the packaging system (aptitude, yum...) to retrieve the last stable version of LibreOffice. This is not mandatory. Under Ubuntu, it is possible by configuring this LibreOffice PPA (=Personal Package Archives):
add-apt-repository ppa:libreoffice/ppa
apt update
In order to install LO, have you added or not the PPA, use the following command.
apt install libreoffice
Managing LibreOffice
This section is important if you are about to deploy a production server. On a developer machine, it can be overkill: I propose you to write this little script, named startlo:
#!/bin/sh
soffice "--accept=socket,host=0.0.0.0,port=2002;urp;"
echo "Press <enter>..."
read R
As a prerequisite for running this script, LO must not be running yet. When running this script, LO will start in server and normal modes: you will see its graphical interface. It means that you will also be able to close it the standard way. While developing, I find this is the most convenient way to use LO.
Before explaining how to manage LO on a production server, you must know that:
- LO is not a "real" server: the complete LibreOffice executable runs, including its UI (User Interface), that is simply hidden, but present. While great improvements have been brought to LibreOffice running in that mode, using LO that way is still a risky business; some elements lack, like a detailed log file, for detecting and analysing errors and warnings;
- there is no built-in control script (the equivalent of an apachectl for example) for automatically or manually starting, stopping or restarting it.
So, in this section, we will create such control script, in the standard system folder /etc/init.d.
cd /etc/init.d
touch lo
chmod a+x lo
Use your favorite text editor to define this content for file /etc/init.d/lo.
#! /bin/sh
### BEGIN INIT INFO
# Provides: lo
# Required-Start: $syslog $remote_fs
# Required-Stop: $syslog $remote_fs
# Should-Start: $remote_fs
# Should-Stop: $remote_fs
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Start LibreOffice server
# Description: Start LibreOffice in server mode.
### END INIT INFO
case "$1" in
start)
cd /home/appy
su appy -c 'soffice --invisible --headless "--accept=socket,host=localhost,port=2002;urp;"&'
;;
restart|reload|force-reload)
pkill -f socket,host=localhost,port=
cd /home/appy
su appy -c 'soffice --invisible --headless "--accept=socket,host=localhost,port=2002;urp;"&'
;;
stop)
pkill -f socket,host=localhost,port=
;;
status)
pgrep -l -f socket,host=localhost,port=
;;
*)
echo "Usage: $0 start|restart|stop|status" >&2
exit 3
;;
esac
exit 0
In this script, 2 elements could be adapted to your needs:
- the port on which LO listens is defined to be 2002 (it is mentioned 2 times, sorry), but another value can be used instead;
- LO is ran with user appy. This is my usual convention and you can use any user you wish. The most important thing is to define users in such a way that files produced by LO can be read and deleted by your Python program running Appy (typically, a web server). For many years, LO and its predecessor, OpenOffice, had to be run with user root (this is not the case anymore). Web servers running Appy were thus not able to delete files produced by LO after being served to web browsers. A script was required to be run every night to delete these temporary files. That being said, with some configurations, you may will still encounter errors while running LO with a non-root user. If you are stuck, consider replacing commands:
cd /home/appy
su appy -c 'soffice --invisible --headless "--accept=socket,host=localhost,port=2002;urp;"&'
with
soffice --invisible --headless "--accept=socket,host=localhost,port=2002;urp;"&
As far as I know, there is no command for stopping a LO server. In the hereabove script, the pkill Unix command is used.
You have noticed that the name of the LO executable is soffice. You may be old enough to remember that LibreOffice's origin was StarOffice, developed by Sun Microsystems. This is why the executable is still named soffice.
Configure your machine to start LO at boot by typing this command (I assume your current working directory is still /etc/init.d):
update-rc.d lo defaults
on RPM-based Linux systems, I guess the command is:
chkconfig --add lo
Congratulations, LibreOffice is installed and configured and is ran at server boot!
The commands for starting, stopping, restarting it or checking its status are:
- /etc/init.d/lo start
- /etc/init.d/lo stop
- /etc/init.d/lo restart
- /etc/init.d/lo status
The previous examples use the following base command to launch LO:
soffice --invisible --headless "--accept=socket,host=localhost,port=2002;urp;"
Here is a more complete variant, known to be used in some production environments. I don't know the precise effect of using these additions, but if you are stuck, consider playing with various combinations of attributes.
soffice --nologo --nofirststartwizard --nodefault --nocrashreport --nolockcheck --headless "--accept=socket,host=localhost,port=2002;tcpNoDelay=1;urp;StarOffice.ServiceManager"
Communicating with LibreOffice
LibreOffice exposes and implements an API called UNO, allowing an external app to send commands and receive data to/from it. POD makes use of this API to perform all the tasks mentioned at the top of this page. In order to be used by a Python program, your Python interpreter must have the python-uno module installed. This module represents the Python bindinds to the UNO API. If you want to check whether your Python interpreter is UNO-enabled, launch it and type:
>>> import uno
>>>
If you do not get any error and see the prompt shown again, your Python interpreter is UNO-enabled.
The cool thing with Ubuntu is that, when installing LibreOffice, python-uno is automatically installed in the Python interpreter (Python 3) as installed by the packaging system.
Using your UNO-enabled app and LO on the same server
The simplest and most performant case is to deploy, on the same machine, you app, based on a UNO-enabled Python interpreter, and a LO server.
This setting corresponds to the Renderer defaults. Renderer attributes that determine communication with LO are the following.
| Attribute | Default value | Description |
|---|
| pythonWithUnoPath |
None |
If the Pyhton interpreter running your app is UNO-enabled, it is not necessary to specify, in this attribute, the absolute path to an alternate Python interpreter being UNO-compliant. |
| ooServer |
'localhost' |
localhost is the convention for representing the current machine. For historical reasons, the parameter is named ooServer and not loServer. |
| ooPort |
2002 |
The Renderer expects LO to listen, by default, on port 2002. |
Using an intermediate UNO-enabled Python interpreter between your app and LO
For various reasons, it may not be possible to run your app with a UNO-enabled Python interpreter. For example, if you are still using Python 2, it is impossible, because communicating with a recent version of LO via UNO can only be done with Python 3. Renderer parameter pythonWithUnoPath allows to specify an alternate UNO-enabled Python interpreter. Such an interpreter is often present within LO distributions. This is the case, for example, on Red Hat or CentOS: the UNO-enabled Python interpreter can be found in locations such as /opt/libreoffice<version>/program/python. The following example makes use of such an alternate Python interpreter.
renderer = Renderer('SimpleTest.odt', globals(), 'result.pdf', pythonWithUnoPath='/opt/libreoffice7.1/program/python')
When the Renderer is run with these settings:
- the Renderer produces a temporary result in ODT or ODS,
- a process is forked, running the UNO-enabled Python interpreter as defined in attribute pythonWithUnoPath,
- this process calls LO via UNO,
- LO does its job, performing the required tasks and producing a file,
- the intermediate process is killed,
- your app retrieves the result as produced by LO.
Using this should be avoided as much as possible.
Using a distant LO
You may want to deploy the LO server on another machine. Before explaining how this can be achieved, you must be aware that, with the hereabove examples, the UNO API is not the sole communication channel between POD and LO. Indeed, the disk is also used to transfer the input and output files. The following example describes the steps involved, and, for each one, the communication channel being used (UNO or disk).
| Step | Initiator | API |
|---|
| 1 |
Here is a file, man! |
POD |
UNO |
| 2 |
I'm reading it, thanks |
LO |
Disk |
| 3 |
The result is ready, my dear |
LO |
UNO |
| 4 |
I'm reading it, thanks |
Your app |
Disk |
Without changing anything to this communication pattern, it means that, when deploying the LO server on another machine, you must define an appropriate mount or network share in order to empower the disk-related steps. If you plan to do so, you will need more precisions about the temporary folders used by POD. Suppose you have the following Renderer parameters.
renderer = Renderer('SimpleTest.odt', globals(), '/path/to/the/result.pdf')
When running it, POD will create a temp folder in /path/to/the that will receive an indigestible name, like
/path/to/the/result.pdf.1619017501.517394
The POD magic will occur in this cooking pot, until the result is produced, in:
/path/to/the/result.pdf.1619017501.517394/result.odt
Then, POD will use UNO to tell LO to open this file. LO will read it from the disk, will do its job and, in the end, will write a PDF file in
/path/to/the/result.pdf
Finally, POD will delete the temp folder and its content.
After this long and boring explanation, it is time to explain how to configure the Renderer with a distant LO server. First of all, you must, of course, set the name of the distant machine in parameter ooServer, like in this example.
renderer = Renderer('SimpleTest.odt', globals(), 'result.pdf', ooServer='distant.machine.org', ooPort=2021, stream=False)
With these precise parameters, you will get the result as described until now: communication with a distant LO via UNO for commands, but via the disk for transmitting input and output files, which requires you to define the appropriate mount.
But, surprise! There is a way to use the UNO API for everything, files included. This is the object of the next section. That being said, keep being suspicious: if I have spent time to write down the current section, this it is not because I needed a good excuse to avoid cleaning tasks. I do not use streams personally, but from what I've heard, using streams seems less performant than using the disk.
Welcome to my streams
LibreOffice's UNO API grants the possibility to transmit input and output files directly via the UNO protocol. So, files are transmitted as streams over the network instead of being dumped to disk.
At the POD level, configuring this is done via the Renderer parameter named stream. Be LO deployed on the same machine or on a distant one, you can choose whatever communication channel you want, as described in the table below.
| Value for Renderer parameter stream | Default ? | Description |
|---|
| "auto" |
yes |
if ooServer is "localhost", exchanging the ODT result produced by the renderer (=the input) and the converted file produced by LO (=the output) will be made via files on disk. Else, the renderer will consider that LO runs on another machine and the exchange will be made via streams over the network. |
| True |
no |
If you want to force communication of the input and output files as streams, use stream=True. |
| False |
no |
If you want to force communication of the input and output files via the disk, use stream=False. |
| "in" |
no |
The input is streamed and the output is written on disk. |
| "out" |
no |
The input is read from disk and the output is streamed. |
You know everything now... Almost.
Indeed, take a deep breath and try to imagine what happens with stream values in the context of a POD template using the pod function to integrate sub-POD templates.
You must know that, everytime a pod function is called from a main POD template, a temporary ODT result is created on disk; in the main POD result, a section that refers to this file is added. Then, via a UNO command, POD asks LO to dispose the section, which means, replacing it with the content of the linked file.
With this in mind, it is clear that POD must ensure that, when LO needs to dispose sections corresponding to sub-PODs, he must find the corresponding files on "its" disk, ie, on the disk of the machine he is deployed on.
The following bunch of diagrams will help getting a complete understanding of what happens between POD and LO when they communicate on separate machines.
Let's start with the basic case: POD and LO are on separate machines, there is no sub-POD, LO is asked to produce a PDF fom an ODT file.
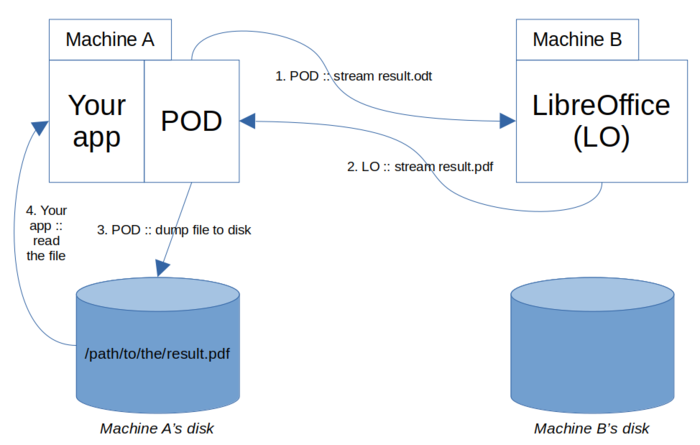
A POD result is sent to LO via UNO (step 1); LO sends back the file being converted to PDF (step 2); POD dumps it on disk, as defined by the Renderer instance; then, your app can access this file.
Imagine now that the POD template integrates a call to function pod. As explained earlier, when POD executes this function, it creates a section in the main result, being tied to a sub-result that is dumped on disk (named sub-result.odt on the following diagram).
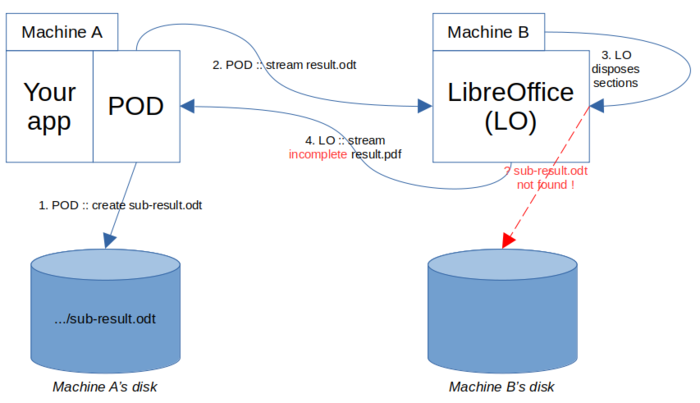
Bad luck: producing sub-result.odt did not require to call LO, so its was created locally (step 1). Then, POD (in step 2) streamed the main POD result to the machine running LO, that, when trying to dispose sections (step 3), did not find sub-result.odt! Consequently, the PDF output being streamed back (step 4) was incomplete. I hear you swear, but remember: we have a weapon to overcome this problem: Renderer attribute forceOoCall. Indeed, if we could tell POD to produce sub-result.odt via LibreOffice, it could save us. Write this idea down on a sheet of paper (we will see later on how to do it concretely) and let's check if this idea saves us.
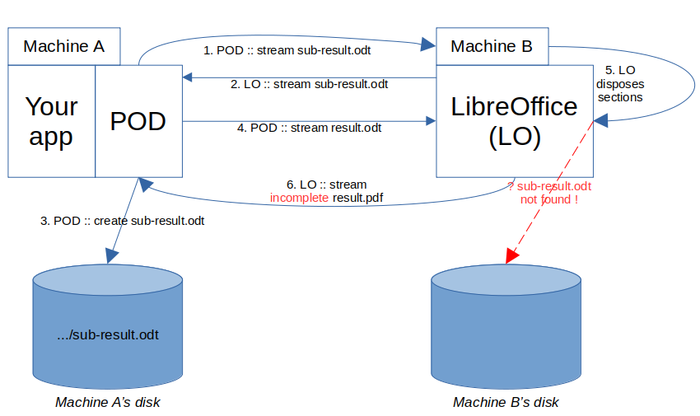
Oh no. Forcing a call to LO for the sub-POD was a good idea (step 1), but using full stream (in and out) for it ended in getting it stored on Machine A's disk (steps 2 and 3). The next steps are similar to the previous diagram: after receiving the main POD result (step 4), when LO tries to dispose sections (step 5), he does not find the sub-result to integrate and returns an incomplete result (step 6).
The last chance we have to fix this problem is... (tell it louder) to use stream "in" only for the sub-result, good answer!
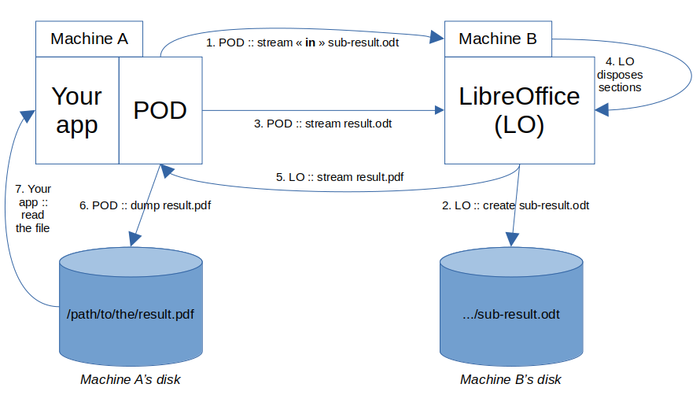
The trick is to send (step 1) the sub-result with stream "in", which implicitly means: "disk out": LO does not stream the answer back, but writes it on its local disk (step 2). When POD asks him to convert result.odt (step 3), during this process, LO disposes a section and finds the tied file on its disk (step 4). It allows him to stream back a complete PDF file (step 5), that POD dumps on Machine A's disk (step 6). Finally, your app may read it (step 7).
You may say: OK, we have the solution, but now, how do we concretely configure the Renderer to achieve this ? The answer is: there is nothing to do. Everything is configured automatically by POD. When running a main Renderer instance, everytime function pod is called, an internal Renderer instance is created behind the scenes (called a sub-renderer). If POD detects that LO is on a separate machine or must be contacted via streams, it will configure the sub-renderer with parameters stream="in" and forceOoCall=True.
You may be furious and wonder why we digged into this level of detail, just to realize that nothing more had to be configured. Be furious. I think that, if you want to adopt this stream-based solution, a deep understanding of the process is required. It allows to understand potential performance issues and empowers you to debug some complex POD templates. Moreover, as a POD developer, you may wonder why POD does not strictly respect you wishes. For example, when using the pod function, you have the possibility to define a value for attribute forceOoCall. This value may be overwritten if POD concludes that forcing a call to LO is required according to these stream in/out issues.
Using a pool of LO servers
All the cases presented so far depict a single LibreOffice server. POD allows you to communicate with several LO servers, provided they all run on the same machine. This machine can be the same as the one running your app + POD, or a distant one.
This is quite simple to configure the Renderer for using a pool of LO servers. Suppose you have 4 LO servers running on the same server as your app, listening on ports 2002 to 2004. Set a tuple or list of ports as value for attribute ooPort, like in the following example.
renderer = Renderer('SimpleTest.odt', globals(), 'result.pdf', ooPort=(2001,2002,2003,2004))
If the server runs on a distant machine, simply add the name of the server in attribute ooServer.
renderer = Renderer('SimpleTest.odt', globals(), 'result.pdf', ooServer='distant.machi.ne', ooPort=(2001,2002,2003,2004))
You may think that, once configured like that, POD will randomly choose one of the specified ports everytime it has to communicate with LO. Shame on you. A nice partner has funded the implementation of true load-balancing between the LO servers.
Here's how it works.
First of all, in the temporary OS folder, the first process running POD and configured to call a pool of LO servers will create a sub-folder at:
<OS temp folder>/appy/lo
This folder is named the pool folder. Everytime a POD-based process or thread uses the POD Renderer to call LO, it will read it to check the status of the LO servers. Based on this info, if he notices that a LO server is not busy, it will choose it and call it. More precisely, POD will perform the following steps:
- write, in the pool folder, a file named <thread_id>.<lo_port>, indicating that the thread having this <thread_id> is currently communicating with the LO server running on <lo_port>;
- call LO;
- remove the file <thread_id>.<lo_port>.
POD determines if a LO server is not busy by reading these files. If all servers are busy, no queue is implemented: POD will nevertheless choose the first server being contacted, which is deduced from the last modification dates as defined on files of the form <thread_id>.<lo_port>. When LO, via UNO, receives a new request while still managing a previous one, I don't know what really happens, in terms of queuing or parallel processing. I assume there is some form of queuing, but no parallel processing, because a LO server is, basically, a LO client running with a hidden UI. But I may be wrong.
This approach has the advantage that load-balancing of LO servers is global to a given machine. Indeed, you may deploy as much POD-powered processes and threads you want, they will all use the same load-balancing info as stored in the machine-wide pool folder. Write conflicts are minimized in this folder, because every thread writes his own files. These files are empty: the only relevant info is in their names.
Moreover, the functionality is implemented in such a way that LO servers can be partitioned. For example, you may implement this configuration:
- deploy 5 LO servers on ports 2002 to 2006;
- configure POD-powered processes A and B to use LO servers on ports 2002 and 2003;
- configure POD-powered multi-threaded process C, to use LO servers on ports 2004 to 2006.
When reading the pool folder, any POD-powered process or thread will ignore any file not being tied to its "own" LO servers.
Running several LO servers
As described earlier on this page, running LibreOffice in server mode is done via a command like this one.
soffice --invisible --headless "--accept=socket,host=localhost,port=2002;urp;"&
If you repeat this command to launch several LO servers, like this:
soffice --invisible --headless "--accept=socket,host=localhost,port=2002;urp;"&
soffice --invisible --headless "--accept=socket,host=localhost,port=2003;urp;"&
you'll get a single LO process listening to both ports 2002 and 2003.
If you want true separate LO processes, each one listening on his own port, you must launch them with this additional parameter:
-env:UserInstallation="file://<folder>"
Set <folder> to be a folder in the OS temp folder. Here is a complete example. Suppose you already have a first LO server running on port 2002. Run a distinct LO server on port 2003 with that command:
soffice -env:UserInstallation="file:///tmp/gdy/2003" --invisible --headless "--accept=socket,host=localhost,port=2003;urp;"&
If folder /tmp/gdy/2003 does not exist, or any of its parent folders, LO will create it.








